We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.
Our SeePhys is now open for submissions at the ICML 2025 Challenge on Automated Math Reasoning and Extensions! To evaluate your model, please submit benchmark results to our website following the official guidelines.
We strongly encourage all participants to concurrently submit their technical reports to the ICML 2025 AI for Math Workshop.

| Rank | Participants | Public (mini) | Private (overall) |
|---|---|---|---|
| 1 | pwrtasoa🥇 | 66.00 | 60.56 |
| 2 | zhaojiahao🥈 | 62.00 | 60.28 |
| 3 | dreamwave🥉 | 66.00 | 58.94 |
| 4 | sjbzmn | 55.50 | 57.83 |
| 5 | sparsh35 | 59.50 | 57.78 |
| 6 | obiwan | 60.50 | 55.00 |
| 7 | phaedrus | 56.50 | 54.22 |
| 8 | skhakim | 56.00 | 50.50 |
| 9 | eonia | 56.50 | 48.78 |
| 10 | stackdreamer | 51.00 | 48.28 |
| 11 | ruizheng | 39.00 | 42.50 |
| # | LLMs | Mid | High | BO | AO | UG | SUG | MA | PhD | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Human Expert🥇 | 100.0 | 94.4 | 92.3 | 71.7 | 92.9 | 94.7 | 100 | 83.0 | 86.5 |
| 2 | DeepSeek-R1🥈 | 54.9 | 46.9 | 47.7 | 31.9 | 49.9 | 34.2 | 49.0 | 41.2 | 42.2 |
| 3 | DeepSeek-V3🥉 | 53.9 | 42.6 | 36.4 | 22.8 | 45.4 | 29.7 | 35.9 | 37.5 | 36.0 |
| 4 | Qwen3-235B-A22B | 47.1 | 33.7 | 31.8 | 20.4 | 41.2 | 25.1 | 31.7 | 30.7 | 31.1 |
| 5 | QwQ-32B | 47.1 | 42.2 | 44.9 | 15.5 | 40.0 | 20.1 | 32.4 | 24.0 | 29.7 |
| 6 | R1-Distilled-Llama-70B | 48.0 | 41.4 | 34.6 | 14.2 | 31.5 | 16.0 | 28.9 | 25.9 | 26.9 |
| 7 | Llama-4-Scout-17B | 48.0 | 36.5 | 31.8 | 11.3 | 28.5 | 14.2 | 28.3 | 26.1 | 24.8 |
| 8 | Qwen2.5-72B | 41.2 | 40.2 | 25.2 | 8.2 | 26.8 | 12.8 | 18.6 | 17.8 | 21.1 |
| 9 | Gemma3-27B | 21.6 | 36.5 | 30.8 | 5.1 | 23.1 | 9.1 | 15.2 | 11.9 | 16.9 |
| 10 | Llama-3.1-8B | 26.5 | 15.7 | 17.8 | 3.9 | 7.6 | 3.7 | 10.3 | 8.4 | 9.2 |
| # | MLLMs | Mid | High | BO | AO | UG | SUG | MA | PhD | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Human Expert🥇 | 100.0 | 94.4 | 92.3 | 71.7 | 92.9 | 94.7 | 100 | 83.0 | 86.5 |
| 2 | GPT-5 (high)🥈 | 75.5 | 70.7 | 70.1 | 55.5 | 65.9 | 63.9 | 60.7 | 60.4 | 63.2 |
| 3 | Gemini-2.5-Pro🥉 | 69.6 | 66.7 | 64.5 | 46.7 | 64.2 | 50.2 | 53.8 | 44.2 | 54.9 |
| 4 | o4-mini | 66.7 | 61.8 | 56.1 | 41.8 | 53.8 | 45.7 | 51.0 | 53.4 | 51.9 |
| 5 | grok4 | 62.5 | 38.9 | 38.5 | 54.3 | 54.8 | 42.1 | 57.1 | 44.7 | 49.0 |
| 6 | o1 | 60.8 | 56.6 | 50.5 | 32.5 | 54.4 | 40.6 | 52.4 | 40.4 | 45.6 |
| 7 | Doubao-1.5-pro | 70.6 | 58.2 | 49.5 | 29.2 | 56.6 | 34.7 | 40.7 | 37.5 | 43.9 |
| 8 | o3-mini | 47.1 | 46.2 | 39.3 | 28.3 | 47.0 | 36.1 | 48.3 | 42.3 | 40.3 |
| 9 | GPT-4.1 | 51.0 | 52.6 | 41.1 | 17.0 | 39.7 | 31.1 | 42.1 | 35.6 | 35.3 |
| 10 | Claude-3.7-Sonnet | 52.9 | 51.8 | 43.0 | 16.7 | 41.4 | 26.5 | 33.8 | 32.4 | 34.6 |
| 11 | Skywork-R1V3-38B | 53.9 | 43.8 | 40.2 | 19.7 | 39.7 | 24.2 | 30.3 | 28.3 | 32.0 |
| 12 | Qwen2.5-VL-72B-Inst | 61.8 | 42.2 | 29.0 | 10.4 | 29.9 | 14.6 | 18.6 | 19.4 | 24.2 |
| 13 | QVQ-72b-preview | 38.2 | 36.5 | 30.8 | 11.3 | 25.9 | 14.2 | 26.2 | 20.2 | 22.5 |
| 14 | GPT-4o | 37.3 | 39.0 | 34.6 | 7.5 | 23.4 | 15.5 | 24.1 | 21.8 | 21.9 |
| 15 | Llama-3.2-90B-Vision | 21.6 | 25.7 | 22.4 | 3.9 | 9.3 | 10.0 | 12.4 | 8.9 | 11.7 |
| 16 | Qwen2.5-VL-7B-Inst | 39.2 | 25.3 | 21.5 | 4.2 | 8.7 | 5.9 | 10.3 | 7.3 | 11.6 |
| 17 | Qwen2.5-VL-3B-Inst | 30.4 | 21.3 | 13.1 | 2.9 | 10.4 | 7.3 | 6.2 | 6.2 | 9.8 |
| 18 | Qwen2-VL-7B-Inst | 24.5 | 17.3 | 14.0 | 4.4 | 8.5 | 4.6 | 10.3 | 7.0 | 9.2 |
| 19 | LLaVA-NeXT-7B | 14.5 | 12.7 | 11.2 | 5.5 | 13.2 | 8.2 | 11.0 | 9.4 | 8.7 |
| 20 | Llama3.2-11B-Vision | 23.5 | 18.5 | 14.0 | 4.2 | 5.4 | 3.7 | 4.8 | 7.5 | 8.3 |
| 21 | Phi-4-multimodal | 20.6 | 12.4 | 12.1 | 4.4 | 7.0 | 5.0 | 8.3 | 4.9 | 7.6 |
| 22 | InternVL2.5-8B | 17.6 | 12.4 | 9.3 | 2.9 | 5.6 | 3.2 | 4.1 | 5.1 | 6.2 |
| 23 | LLaVA-OneVision-7B | 20.6 | 10.8 | 12.1 | 2.7 | 5.4 | 2.3 | 6.2 | 5.4 | 6.1 |
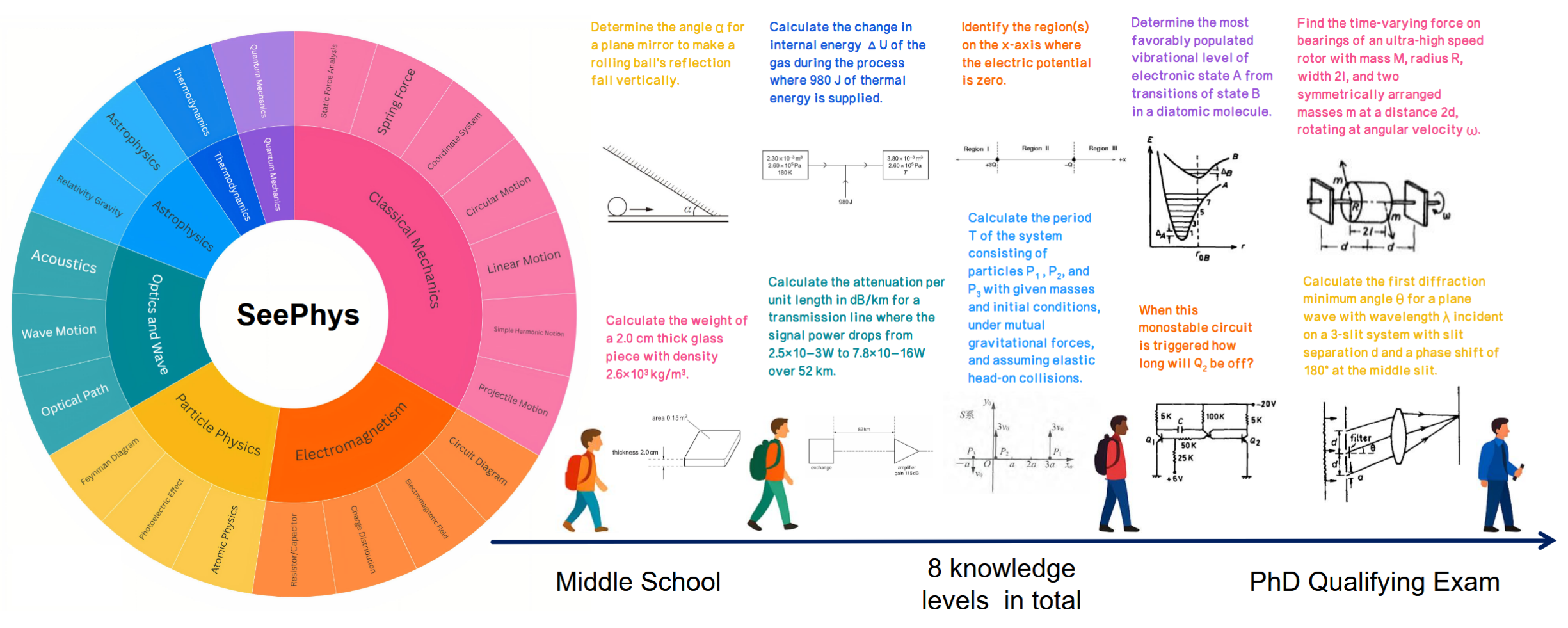
Overview of SeePhys. It encompasses 7 core physics domains and 21 diagram types, spanning the full knowledge spectrum from middle school to PhD qualifying exams levels.
SeePhys comprises 2,000 rigorously validated questions covering a comprehensive range of knoledge levels from middle school to PhD qualifying exam levels. These questions span 7 major fields of both classical and modern physics. To assess the extent to which different models rely on visual information for reasoning, we curate two subsets with different visual information enrichment and additionally compile supplementary copies of 2,000 purely visual instances where all problem statements in texts are presented in picture form. Through meticulous selection of 21 diagram types by domain experts, each problem challenges frontier MLLMs to integrate domain knowledge with visual understanding of physics diagrams (e.g., Feynman diagrams for particle interactions and Circuit diagrams for Electromagnetism).
You can download the dataset on Hugging Face Dataset.
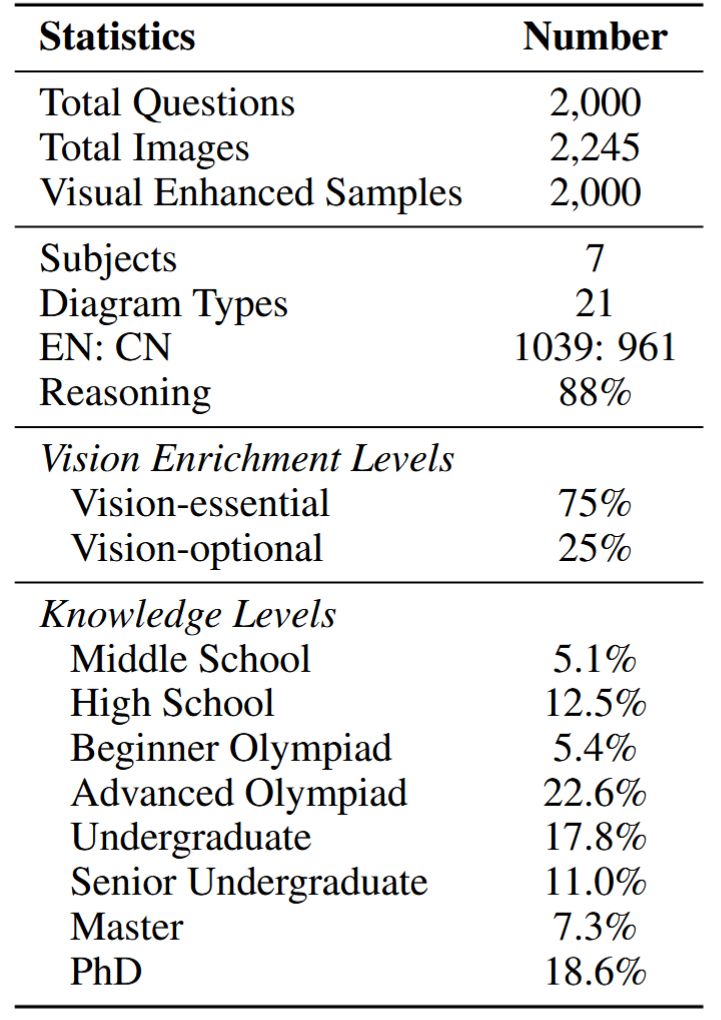
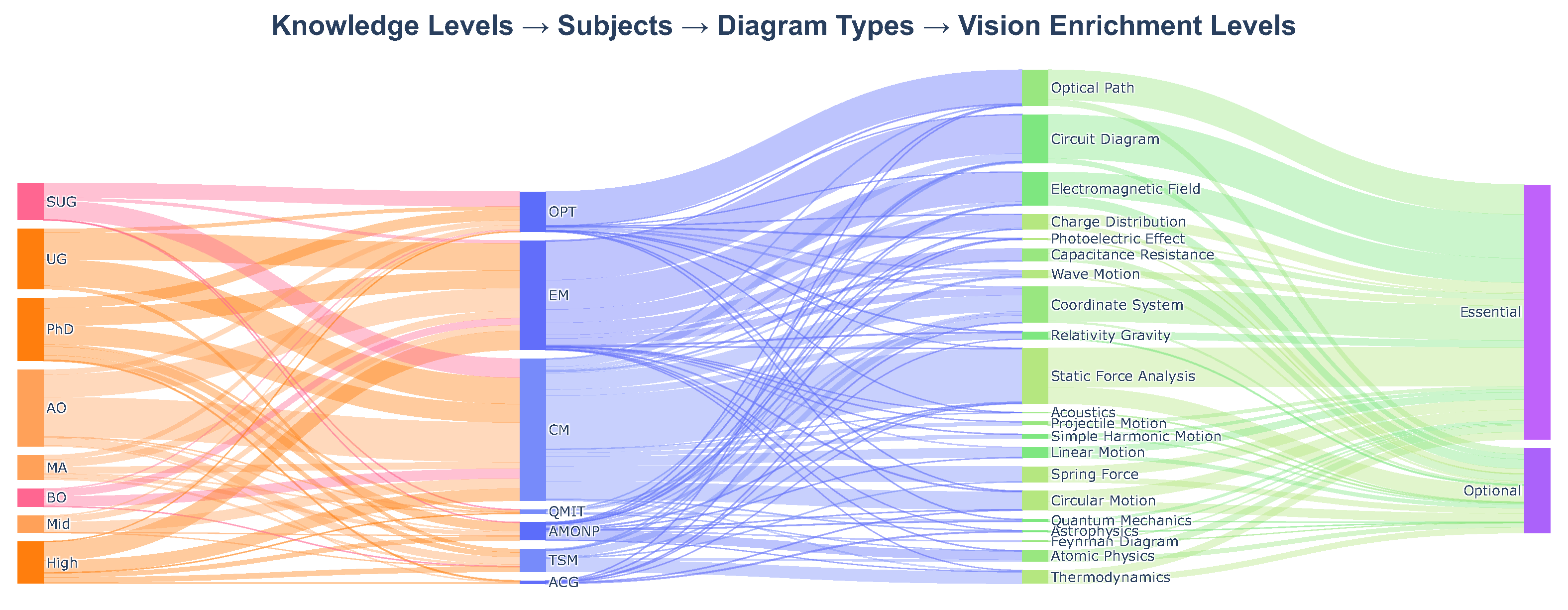
The statistics of ![]() SeePhys dataset.
SeePhys dataset.
![]() The above figure shows in detail the statistics of our SeePhys. The questions span 7 core physics fields and are stratified across 8 knowledge levels from middle school to PhD qualifying exams. Notably, 18.6% of problems target PhD-level reasoning, while 22.6% represent advanced Olympiad challenges. The benchmark emphasizes multimodal reasoning: 75% of questions are Vision-Essential, which necessarily requires diagram interpretation for solving (e.g., analyzing Feynman diagrams), while 25% are Vision-Optional, where visuals supplement text. Questions are language-balanced (1,039 English vs. 961 Chinese) and 88% have multi-step reasoning annotations, validated via expert annotation. Visual diversity is ensured through 21 diagram types (e.g., circuit schematics, free-body diagrams), curated by domain experts. The dataset's composition supports granular evaluation of MLLMs' physics understanding across textual, visual, and reasoning dimensions.
The above figure shows in detail the statistics of our SeePhys. The questions span 7 core physics fields and are stratified across 8 knowledge levels from middle school to PhD qualifying exams. Notably, 18.6% of problems target PhD-level reasoning, while 22.6% represent advanced Olympiad challenges. The benchmark emphasizes multimodal reasoning: 75% of questions are Vision-Essential, which necessarily requires diagram interpretation for solving (e.g., analyzing Feynman diagrams), while 25% are Vision-Optional, where visuals supplement text. Questions are language-balanced (1,039 English vs. 961 Chinese) and 88% have multi-step reasoning annotations, validated via expert annotation. Visual diversity is ensured through 21 diagram types (e.g., circuit schematics, free-body diagrams), curated by domain experts. The dataset's composition supports granular evaluation of MLLMs' physics understanding across textual, visual, and reasoning dimensions.
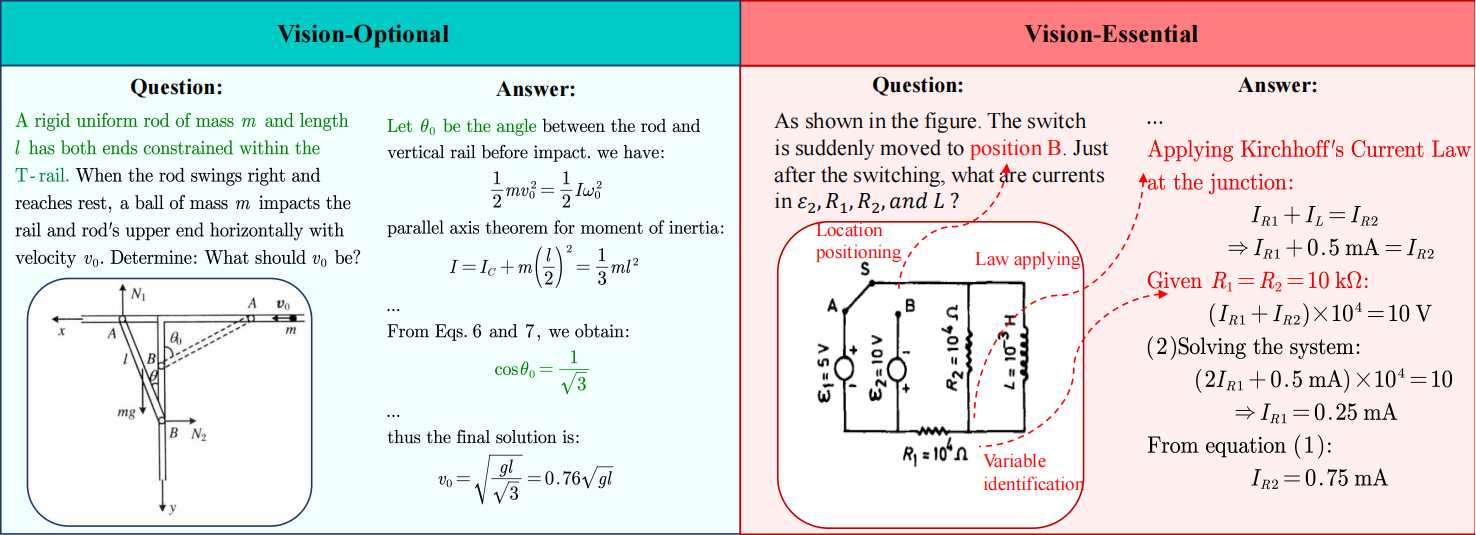
Examples of Vision-Optional/Vision-Essential questions. In Vision-Optional samples, texts provide sufficient visual descriptions (e.g., graphical attributes and spatial relationships) to help respondents with illustration. In Essential samples, images contain indispensable problem-solving information, such as numerical values for key variables and unspecified topological structures.
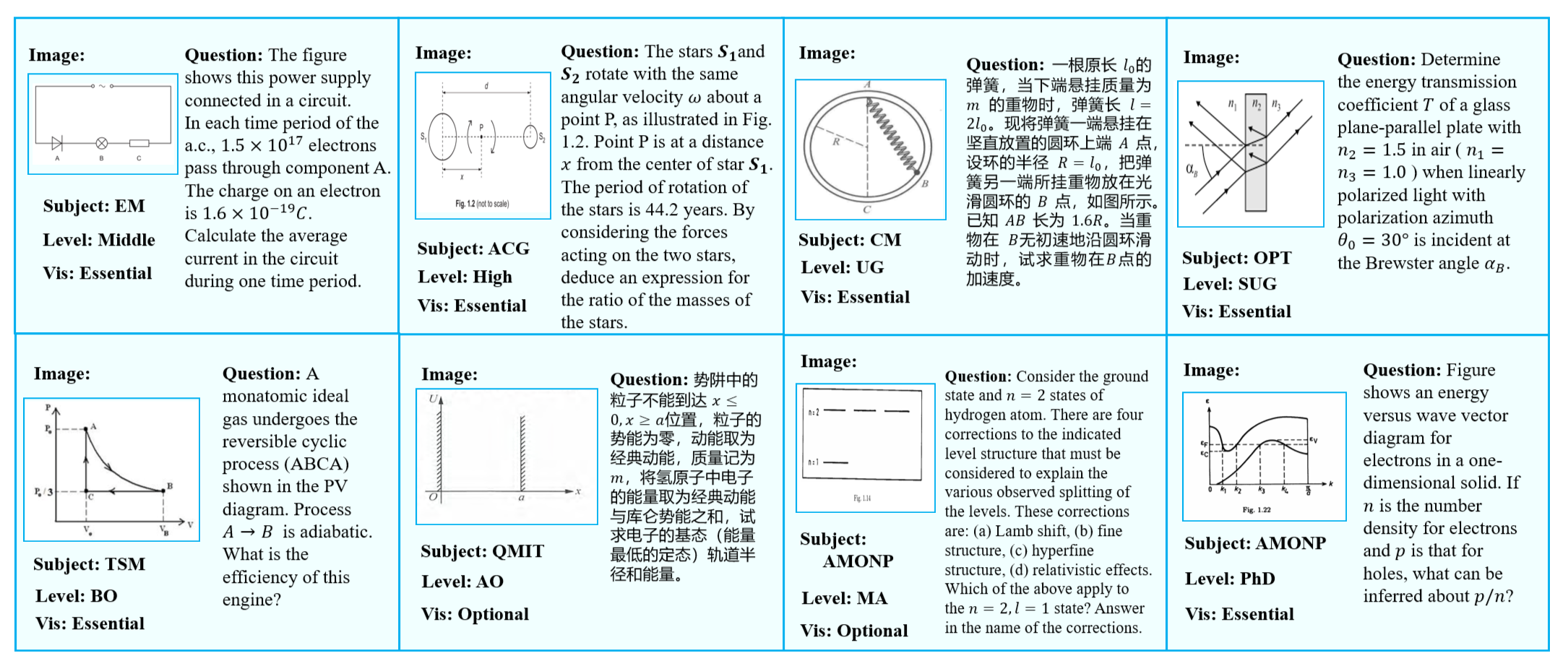
Cases of our SeePhys
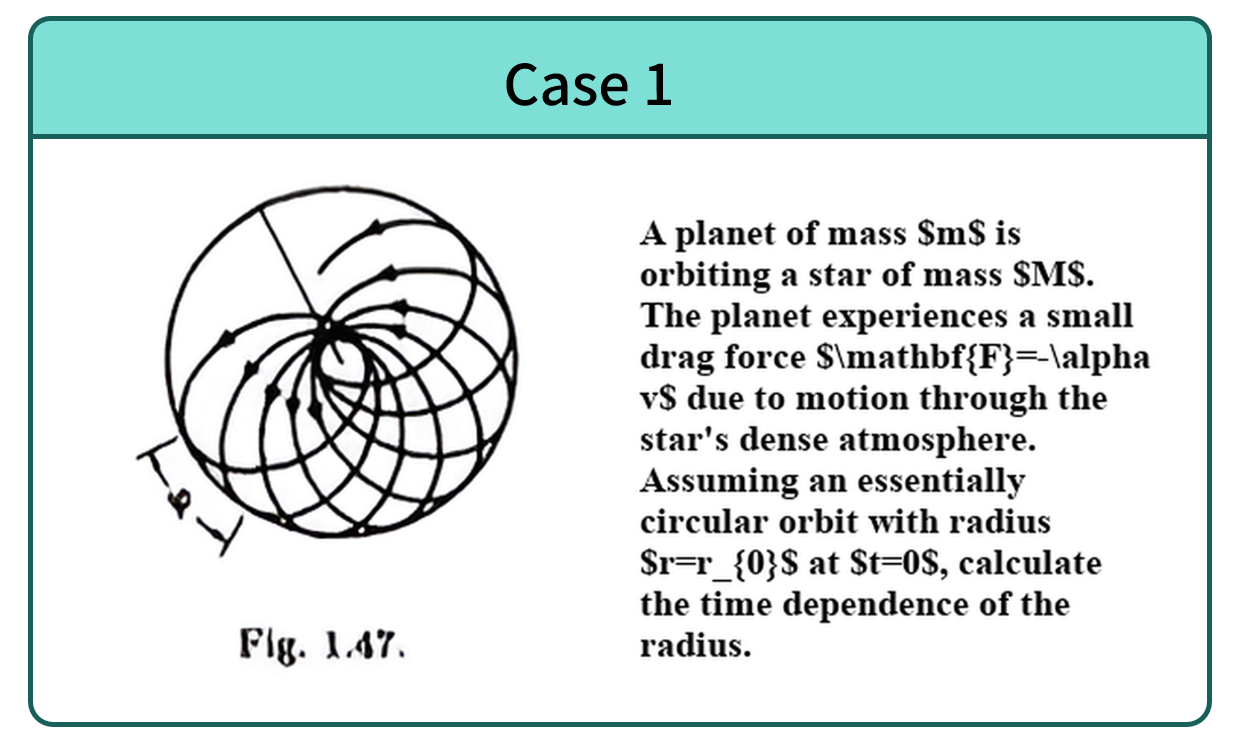
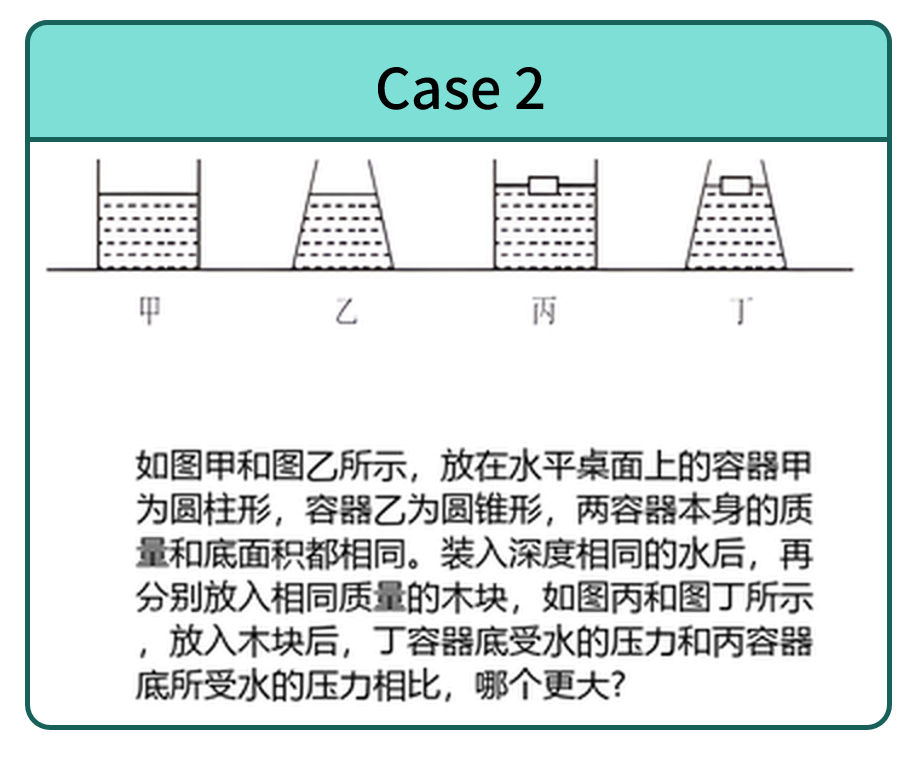
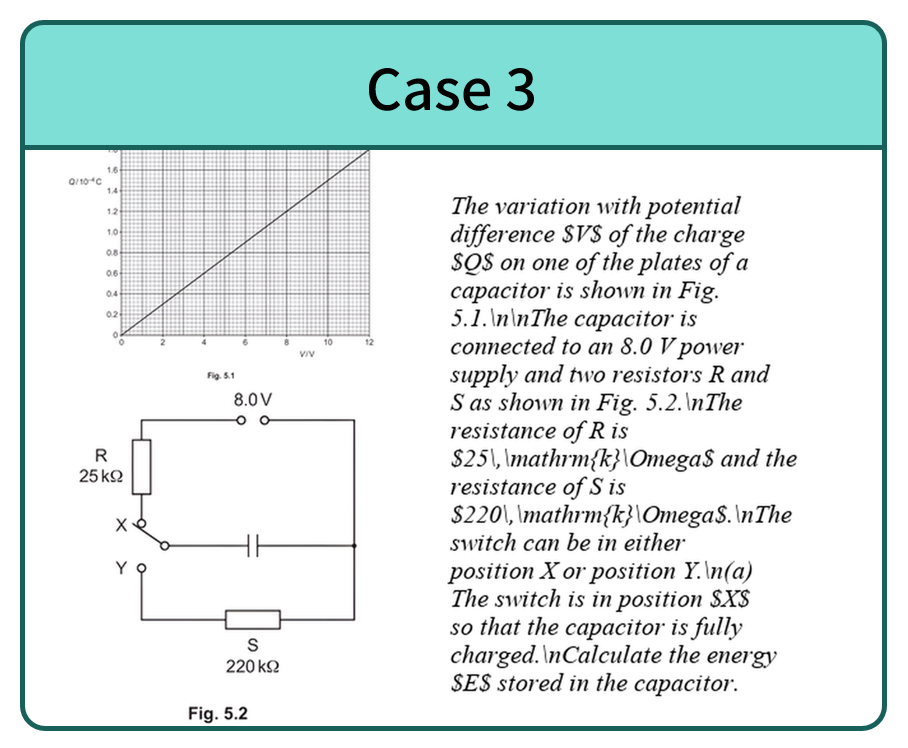
Cases of pure multimodal subset.
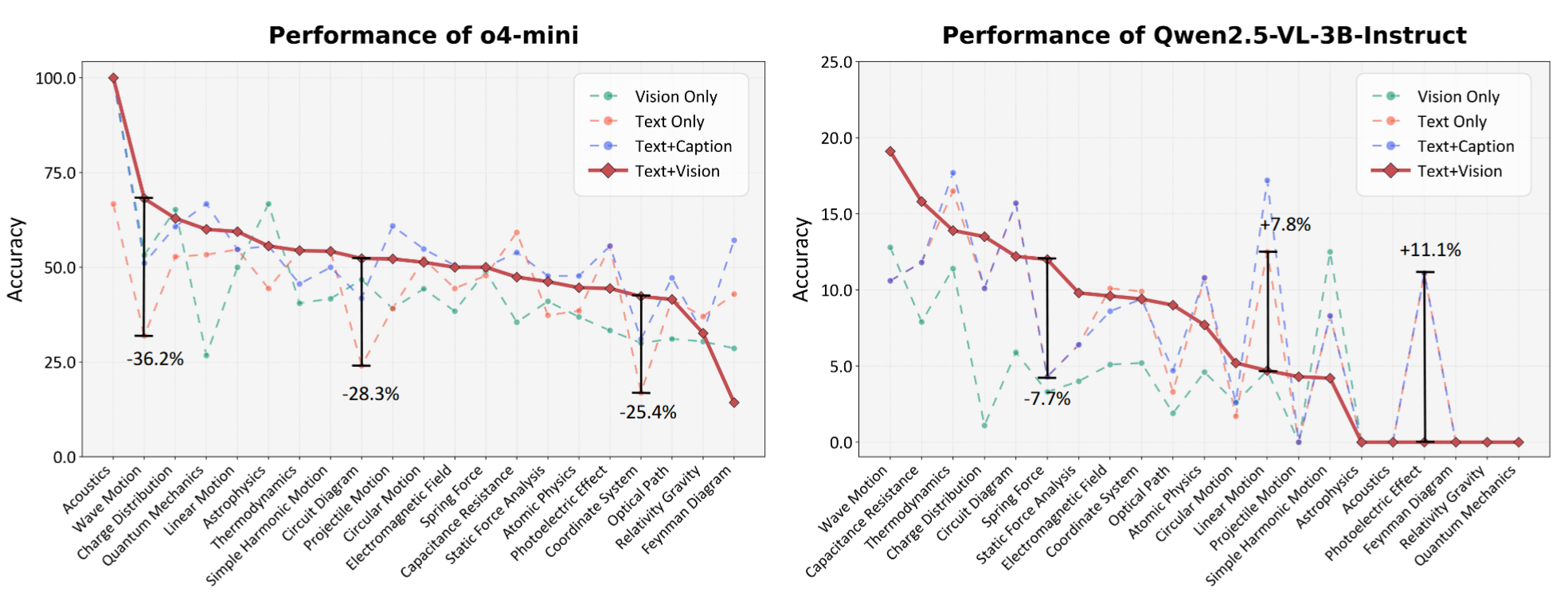
The sensitivity of models to different diagram types under TV/TC/TO/VO settings.

Error patterns comparison of o4-mini, Gemini-2.5-Pro and Qwen2.5-VL-3B. We identify the following error patterns in the models’ outputs: VM: Visual Misinterpretation; TM: Text Mis- interpretation; MF: Modeling Flaws; FA: False Assumption; NM: Numerical Miscalculations; OS: Oversimplification; SM: Summarization Mistakes; OT: Overthinking; RO: Repetitive Output
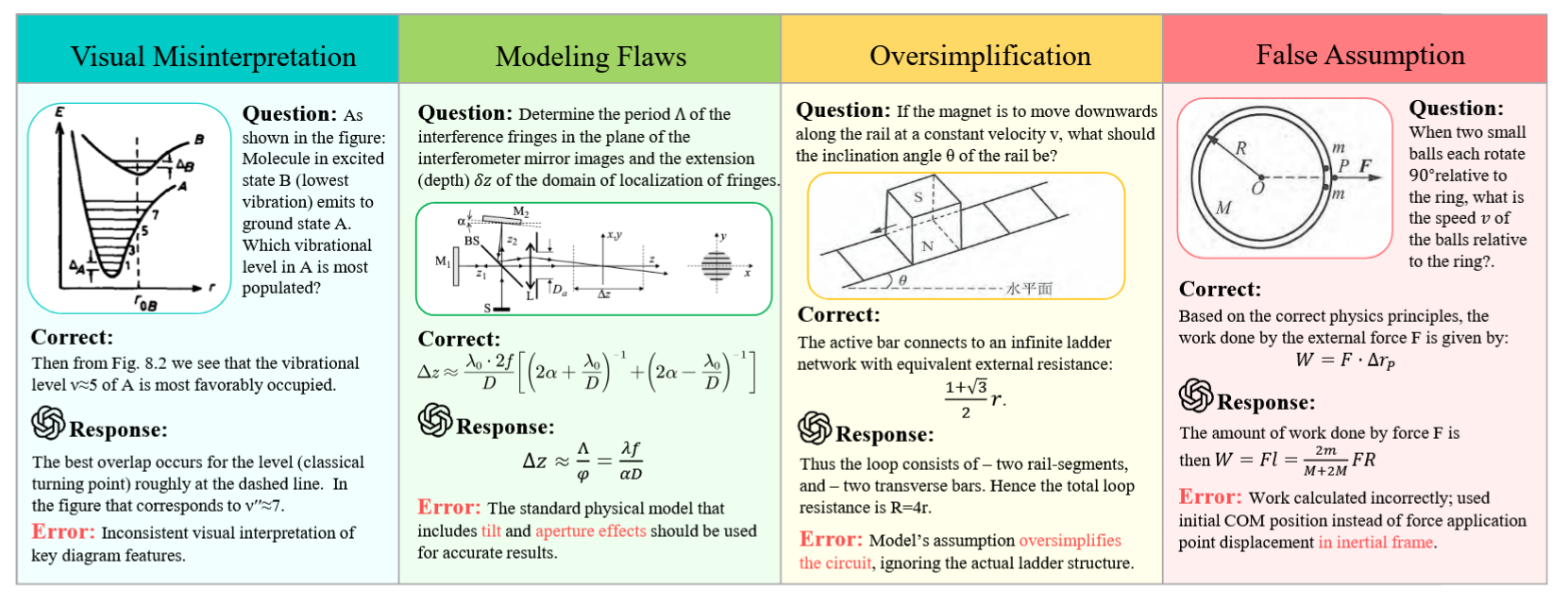
Examples of primary error patterns.
@article{xiang2025seephys,
title={SeePhys: Does Seeing Help Thinking?--Benchmarking Vision-Based Physics Reasoning},
author={Kun Xiang*, Heng Li*, Terry Jingchen Zhang*, Yinya Huang*, Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, Mrinmaya Sachan, Xiaodan Liang},
journal={arXiv preprint arXiv:2505.19099},
year={2025}
}
